Вольный перевод статьи.
Как метрики определили DevOps
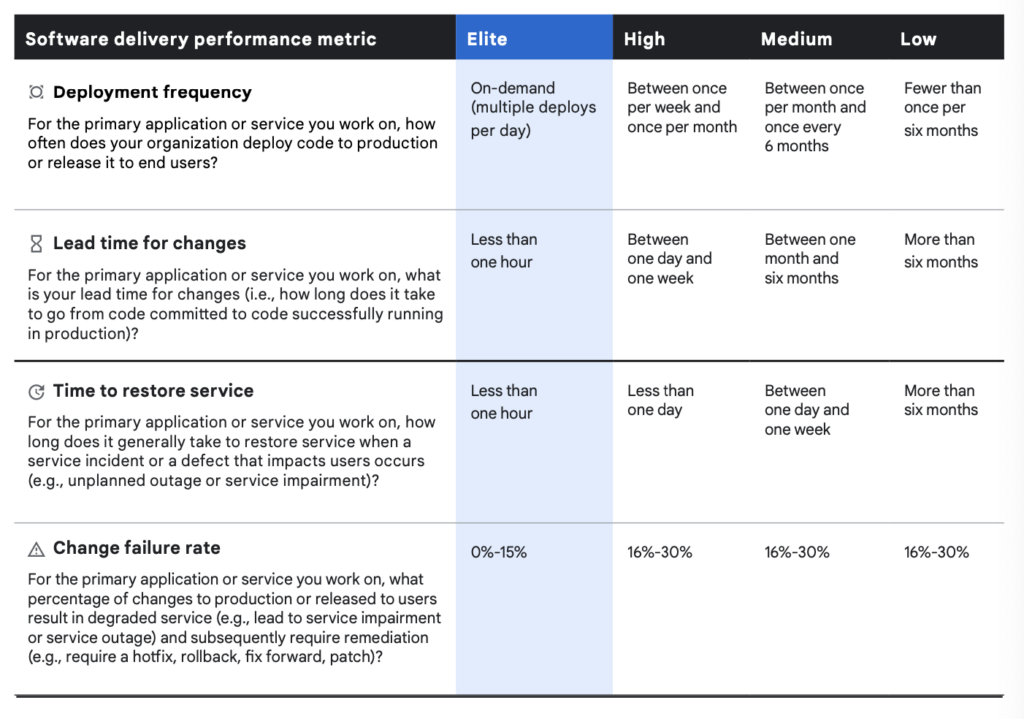
начало положила команда DevOps Research and Assessment (DORA), Они выделили четыре ключевых метрики, которые являются основой для измерения успеха
Deployment Frequency: (частота развертывания) относится к частоте успешных выпусков программного обеспечения в производство. Этот показатель измеряет, как часто команда выпускает и успешно разворачивает новые версии программного обеспечения в рабочей среде. Высокая частота развертывания может указывать на более частые итерации разработки и доставки, что в свою очередь способствует более быстрой реакции на изменения и потребности пользователей, а также улучшению общей эффективности процессов DevOps.
Lead Time for Changes: (время выполнения изменений) измеряет время, прошедшее с момента фиксации изменения кода (например, коммита) до того момента, когда это изменение становится готовым для развертывания (в развертываемом состоянии). Этот показатель позволяет оценить, насколько быстро команда может превратить кодовое изменение в рабочее приложение, готовое к развертыванию в производственной среде. Уменьшение времени выполнения изменений обычно способствует более быстрой и эффективной разработке и доставке программного обеспечения.
Mean Time to Recovery: Среднее время восстановления (Mean Time to Recovery, MTTR) измеряет время, прошедшее с момента возникновения прерывания из-за развертывания или сбоя системы до полного восстановления работы системы. Этот показатель помогает определить, насколько быстро команда может восстановить работоспособность системы после возникновения проблемы или сбоя. MTTR является важной метрикой для оценки эффективности инцидентного управления и улучшения процессов восстановления.
Change Failure Rate: Показатель частоты неудач при изменениях (Change Failure Rate) указывает, насколько часто изменения или исправления (hotfixes), внесенные командой, приводят к сбоям или отказам после развертывания кода в производственной среде. Этот показатель является важной метрикой в контексте DevOps и оценивает надежность и стабильность процесса развертывания и обновления программного обеспечения.
Больше информации тут:
С момента публикации книги «Accelerate» команда LinearB увидела, как работа DORA преобразила область DevOps. Однако вскоре стало понятно, что четыре ключевых метрики DORA в одиночку недостаточно для измерения разнообразных и растущих организаций, практикующих DevOps.
DORA helped DevOps move from “darkness to visibility.” But once there’s full illumination, leaders need a full understanding of what makes one team more effective than another — and what characterizes the top tier of development teams that are truly elite.
LinearB co-founder and CEO Ori Keren
Что не так с DORA метриками ?
- DORA являются отстающими индикаторами, проще и более эффективно выявлять тенденции и предпринимать превентивные действия, чем спешить исправлять ошибки после неудачных итераций.
- Метрики DORA не точно измеряют бизнес-влияние. В пример приводится супер заряженная машина, которая идеально работает, но едет в другом направлении. Некоторые метрики, такие как время цикла и частота развертывания, важны для внутренней команды, но не имеют смысла для бизнеса в целом. Разработчики заботятся о относительной скорости разделов кода (как бы маленьких они ни были), чтобы обеспечивать плавную работу своего пайплайна, но руководители бизнеса хотят видеть всю функциональность — постоянно и как можно чаще. Скорость не имеет значения, если нет согласования с остальным бизнесом и команда не предоставляет то, что сделает клиентов счастливыми.
- Метрики DORA являются важными показателями текущего состояния, но они не являются планами изменений; они являются отправной точкой.
The New Metrics
Для того чтобы внести изменения в инженерные команды, исследование от LinearB выявило 10 метрик внутри 3 групп, которые имеют наибольшее значение в современной методологии DevOps.
- Жизненный цикл доставки ( Delivery Lifecycle Metrics )
- Рабочий процесс разработчиков ( Developer Workflow Metrics )
- Согласованность с бизнесом ( Business Alignment Metrics )
Delivery Lifecycle Metrics
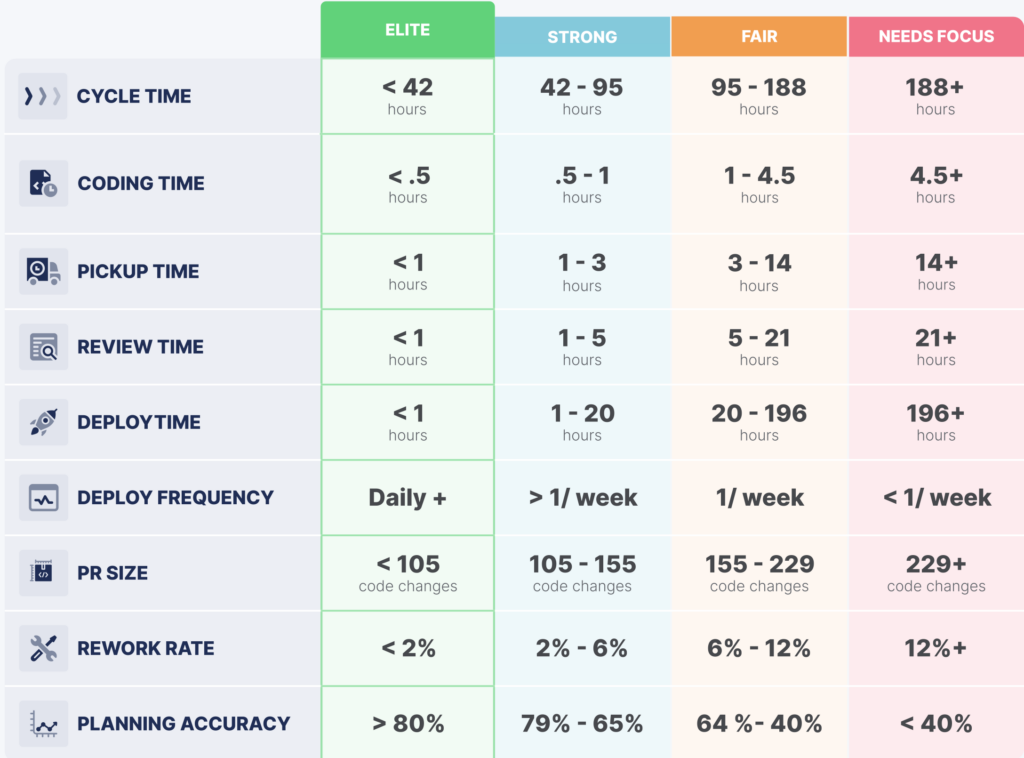
- Время цикла (Cycle time)
Время цикла (часто синоним Lead Time изменений ) является одной из четырех ключевых метрик DORA. Оно представляет собой время, прошедшее с момента первого коммита до момента, когда изменение достигает пользователей, охватывая время написания кода, время подбора задачи, время ревью и время на деплой.
Эффективное время цикла для элитных команд составляет менее 42 часов.
- Время кодирования (Coding time)
Эта метрика измеряет время, затраченное с момента начала первого коммита до выдачи запроса на слияние (pull request, PR).
Для элитных команд время кодирования — менее 30 минут.
- Время подбора (Pickup time)
Это время начинается после выдачи запроса на слияние (PR) и заканчивается после того, как будет оставлен первый комментарий.
Для элитных команд время подбора составляет менее 1 часа.
- Время рецензии (Review time)
Эта метрика охватывает процесс рецензии кода и слияния PR, начиная с первого комментария и заканчивая моментом, когда изменения объединяются с основной веткой кода.
Для элитных команд время рецензии составляет менее 1 часа
- Время развертывания (Deploy time)
Это измерение времени с момента слияния ветки (branch merge) до момента выпуска кода.
Для элитных команд время развертывания составляет менее 1 часа
“Cycle time is an engineering super metric.”
Ori Keren Co-Founder & CEO LinearB
Developer Workflow Metrics & How Elite Teams Perform
- Частота развертывания (Deploy frequency)
Эта метрика измеряет, насколько часто код выпускается в производство. Она выше, когда время развертывания (deploy time) ниже. Ее также можно рассматривать как функцию времени цикла (cycle time).
Элитные команды делают деплой кода ежедневно.
- Размер пул реквеста (PR)
Это, безусловно, один из наиболее важных ведущих индикаторов здоровой разработки. Меньшие PR = более быстрое восприятие, более быстрые и более глубокие рецензии, более быстрые слияния и более высокая частота развертывания.
В элитных командах в среднем менее 105 изменений кода в их PR.
- Уровень «брака» (Rework rate)
Эта метрика измеряет уровень изменений в коде (code churn). Переделывание относится к изменениям в коде, возникшим в коде, который старше 21 дня. Более высокие уровни переделывания могут быть индикаторами проблем с качеством.
У элитных команд уровень переделывания составляет менее 2%.
Business Alignment Metrics
- Точность планирования (Planning accuracy)
Эта метрика определяет, насколько точно выполнено планирование, то есть насколько совпадает то, что было запланировано, с тем, что было фактически доставлено.
Элитные команды имеют точность планирования 80% и более.
- Точность определения объема (Capacity Accuracy)
Точность определения объема показывает, берут ли ваши команды «правильное» количество работы. Эта метрика измеряет соотношение всех завершенных (запланированных и незапланированных) задач к запланированной работе.
Элитные команды имеют точность определения объема более 85%.
Это означает, что они эффективно управляют рабочей нагрузкой, беря на себя необходимое количество работы и успешно завершая ее.
PS: остаток статьи маркетинг
PPS: Accelerate State of DevOps 2021